
Code coverage is a way to measure how much of an application’s source code is covered by a test suite. It’s a tool that can be used in assessing the quality of an application.
Like any tool, it can be used or abused. I have frequently encountered code-coverage stats abused in ways that become detrimental to a team’s output and moral.
What is Code Coverage
In its simplest form, it’s a percentage metric that reports on how many lines of application source “code” are being “covered” during test execution. I’ve often seen it on dashboards where it’s paraded around as some sort of stand-alone indicator of success.
This is the first form of abuse: Referencing it as a value without any additional context.
Metrics Without Context
Code coverage percentages don’t mean anything on their own. They don’t intrinsically designate high or low quality, they are simply an indicator.
Using “X % Code Coverage” as a measure of quality is akin to using “Days of Work” as a measure of development velocity; it’s a meaningless number. If I state that I do “One day of work per day”, that is an unhelpful measure.
\[Velocity = 1day/day\]Mathematically, the day units cancel out and we’re left with a dimensionless quantity.
So too it is with code coverage statistics; percentages are simply an indicator of where to focus attention.
Chasing a Target Percentage
This is another abuse of code coverage; charging a team with meeting an arbitrary coverage percentage. Why is that an abuse? Because getting additional test coverage for the sake of additional test coverage is easy.
If the objective to chase is a meaningless number, then writing meaningless tests is the fastest way to achieve that. So don’t chase target numbers. Chase target areas.
Coverage as a Guide
A practical use of code coverage is to use it as a guide to narrow down high-value areas to target for testing. This involves drilling-down into line coverage to examine which execution flows are not being covered by tests.
Where do we know to drill-down? A combination of critical-components and coverage statistics. Identify parts of the application that are critical, and use low coverage statistics to prioritise additional tests. Now we’re using data with context!
Every application is different, so what is deemed “critical” will vary wildly. If an application has low test coverage over a bunch of files that are used as dumb data-transfer-objects, maybe leave it alone. But if low line-coverage exists over something like a core controller, or an authorisation policy, maybe focus one’s energy there instead!
Identify Failure Paths
Another great use of code coverage is to help uncover failure paths that have not seen any test coverage. Untested failure paths are where an application will behave erratically and unpredictably. Exception handlers, back-off strategies, initialisers, things of this nature. This can offer valuable insight into where to focus additional efforts in bolstering application quality.
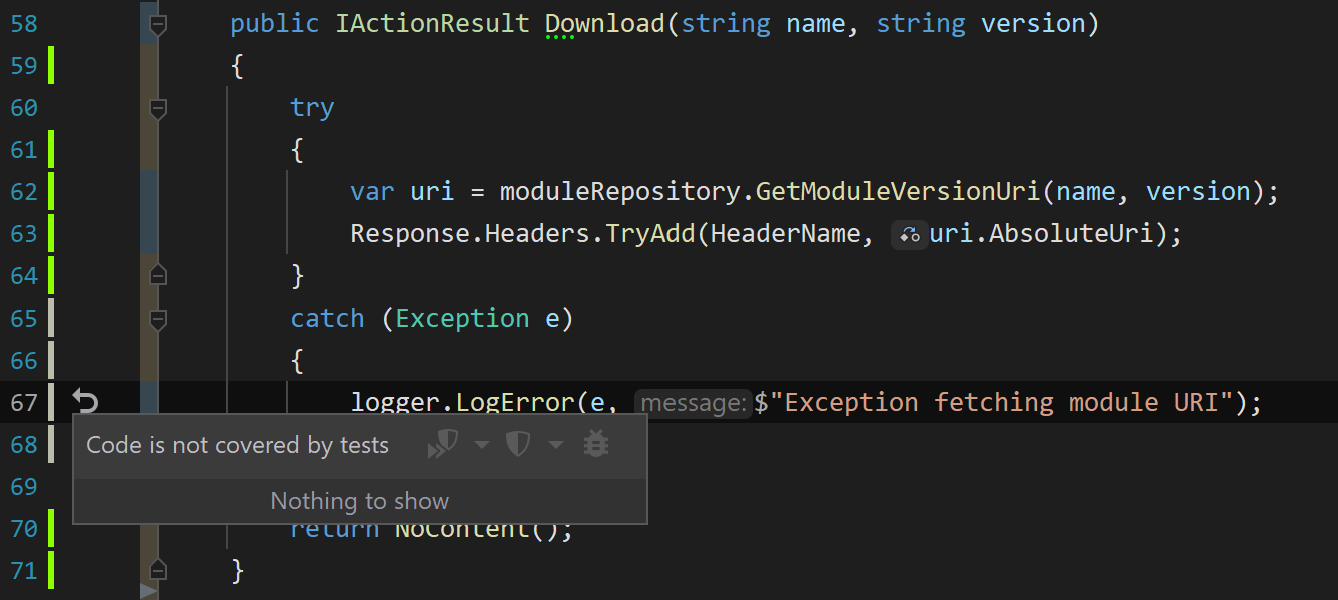
Don’t publish coverage outside the team
Somewhat akin to team velocity measures, code-coverage shouldn’t be paraded around outside the team. Nor should it be “weaponised” to compare “perceived quality” between two teams. Treat this information the same way a doctor might treat a patient’s vitals-chart. Informative and useful for sure, but also private.
Conclusion
I had no idea that “Code Coverage” was a trigger-phrase of mine. When a work colleague asked me for my thoughts on it, well, it turns out I had a few thoughts to give! I hope some of these prove useful to others.
Attributions:
-
Banner background by rawpixel.com on Freepik
-
Coding man photo by pressfoto on Freepik